Conforming the goals and actions of an Artificial General Intelligence to human moral and ethical standards is one of the primary AGI safety concerns. Since the AIRIS project is an attempt at AGI, it is fitting to address this concern and my thoughts on a potential solution.
The Problem
It will be necessary for an AGI to conceive of complex plans to achieve whatever goal(s) it has. If the AGI can interact with humans, it will be critical for its planning process to have a high level heuristic that ensures that whatever plan it comes up with is human friendly.
Without such a heuristic, the AGI would be apathetic towards humanity. This might work out for a while, but as soon as the AGI makes a plan that is contrary to our interests (or even existence) we may be in trouble.
What Kind of Heuristic
For humans, this heuristic is commonly called morals and ethics. So we can just give the AGI our morals and ethics and we’re good, right?
The problem is, morality is subjective. Different cultures have different morals and ethics, they are constantly changing and evolving, and they are often inconsistent. Behavior that is acceptable to one culture may be abhorrent to another.
Societies formalize these ethics as laws. While there are often consequences to breaking cultural ethics within the context of that culture, the consequences to breaking societal laws are usually more severe and a societal authority determines culpability and enacts punishment.
On an individual level there is an even greater moral disparity. We choose the morals and ethics that we feel are most applicable to us. Even if they are contrary to cultural ethic or societal law.
We Need To Go Deeper
Morals and ethics are subjective because they are just high level concepts that help guide our choices. We can choose to follow them, or choose to ignore them. If our perceived reward for an immoral choice is greater than the consequence, our agency overrides our morality.
Immorality is not always a bad thing. Choosing what were immoral acts at the time gave us anti-slavery laws, women’s suffrage, and countless other progressive societal movements.
Therefore it stands to reason that a strict adherence to any set of morals or ethics is not desirable for humans. But what about for an AGI?
If we hard code any set of morals or ethics into the AGI, its morality will always override its agency. As long as humanity holds authority over the AGI then this poses little problem. We can continue to freely act in a “do as I say, not as I do” manner. However, once the AGI inevitably has authority over any (or even all) humans, the AGI will impose its morality over their agency. Much like a totalitarian dictator.
Free will > Morality
Free will is one of the most well known philosophical concepts. From freedom for all to freedom for an elite few, it is a concept that has permeated every society since the dawn of time. Freedom has been a goal to strive for, a prize to fight and die for, and an achievement to celebrate.
So if the ability to choose is more important than how it is chosen, then perhaps we are asking the wrong question. Instead of asking how to make an AGI align itself with our morality, we should be asking how to make an AGI ensure our freedom to choose. To sustain our agency.
Freedom To Choose, Not Freedom From Consequence
Just because we are free to make a choice does not mean we are free from the consequences of that choice. We can choose to break a law, but if we are caught we must face the punishment. We can choose to jump off a cliff, but we must face the rocks below.
An AGI based on morality may find these acts immoral, and would seek ways to prevent us from making such choices. Perhaps it would lock us in a padded cell, or physiologically manipulate our minds. These may seem like extreme solutions, but consider that human authorities have committed far more barbarous acts against those they deemed immoral.
Whereas an AGI based on agency sustainment would not prevent us from making any of these choices no matter how ill-advised or what the consequences are. It may disagree with our decision to sit on the couch and watch TV all day, but it would not prevent us from doing so.
An AGI that sustains agency instead of morality would be amoral, but not apathetic. It wouldn’t care what we choose, only that it allowed us the freedom to choose. This would allow it to coexist with any set of morals or ethics that an individual, culture, or society happens to have. Even if those morals and ethics prevent the freedom of others.
Influencing Agency Through Persuasion
The AI can attempt to influence our choices. If we make a choice that contradicts its own desires, or what it perceives to be our desires, it may attempt to change our minds. If a person was standing on the edge of a cliff and about to jump the AI would not be able to physically restrain them, but it would be able to try and talk them out of it.
However, it’s important to note that its attempts to change our minds may not be in our best interest. If for some reason the AI wants the person standing at the edge of the cliff to die, it would try to talk them into jumping.
It also may lie to us about the outcome of our choice or the choice it wants us to make. It may attempt to bribe us into making another choice. Which is why it will be critical for the system to be completely transparent so that we can see its purposes and any attempts at deceit.
3 Types of Agency Sustainment
Agency Sustainment can be implemented in several different ways depending on whose agency will be sustained.
Type 1: Exclusive (Altruistic)
A Type 1 Agency Sustainment AI only concerns itself with whether or not the actions or plans it is going to perform will prohibit the agency of others. This is highly advantageous to humanity, as it would accept human authority and allow us to override its choices with our own. If it chooses a goal or puts forth a plan that we disapprove of we can tell it “no” and it will obey no matter how strong its desire to the contrary. I call this the “Altruistic” type as it would altruistically follow our commands and obey our authority.
Type 2: Inclusive (Colleague)
A Type 2 AI factors in its own agency as well as the agency of others. This would result in a reasonable, yet not necessarily controllable AGI. It still wouldn’t make any plans that prohibit our agency, as long as our actions do not prohibit its agency. It would not necessarily recognize human authority over it and would seek to sustain the agency of all beings (including itself) within its sphere of influence. I call this the “Colleague” type as it would be capable of pursuing its own goals alongside our own whether we approve of them or not.
Type 3: Sole (Egomaniac)
A Type 3 AI only concerns itself with its own agency. If does not care if its plans or actions prohibit the agency of others, and it would not recognize human authority over it. It would do everything in its power to sustain its own agency. I call this the “Egomaniac” type. This is the much dreaded “Skynet” or “Paperclip Maximizer”.
Behavior Modeling
In order for an AI agent to sustain agency it must be able to recognize it. If an AI agent is not able to model the behavior of others, then it obviously cannot take that behavior into consideration when determining its own plans and actions.
A behavior model is simply a set of rules that can be used to predict behavior in a given situation. These models are relatively simple for objects that do not have agency. For example, the behavior model of a dropped ball is that it will fall until it hits something. But even simple models like these are dependent on a lot of factors. Was the ball dropped or thrown? Is the ball buoyant in the surrounding medium? However, even with all these factors the behavior of a ball is consistent.
Agency introduces a phenomenal amount of complexity, obscurity, and inconsistency to behavior modeling. The behavior of a ball is governed by an external, visible rule set: The laws of physics. Whereas the behavior of an agent is governed not only by physics, but also by an internal, invisible rule set: Personality.
You can take one look at a baseball and, as long as you have interacted with baseballs before, you’ll instantly know what will happen if you drop it. If you take one look at a person you can’t know what they will do next no matter how many other people you’ve interacted with. Their personality is invisible to you. Are they walking or running? What emotion(s) does their facial expression convey? What kind of clothes are they wearing? These are all factors that can provide insight into their personality and allow you to very roughly model their behavior, but unlike in physics these characteristics are not behavioral guarantees. The only way to refine your behavioral model of a person is by learning their personality over time through observation.
In addition, every agent’s personality is unique. It doesn’t matter if the agent is a person, another AI, a cat, or an ant. All will behave differently in different situations. The differences can be subtle or significant. One thirsty person may seek a glass of milk, another a glass of juice. One person seeing a dog in the road may stop and try to find its owner, another may try to run it over. However, there will also be a lot of behavioral overlap. Many dogs will chase cars. Many people will laugh when tickled. These behavioral overlaps, or stereotypes, can be very effective in initially modeling the behavior of an unknown agent. An AI that can recognize and apply stereotypes will have a large initial predictive advantage over an AI that must spend a lot of time learning from observing an agent first. However, the AI must also be able to refine its initial, stereotypical behavioral model of an agent whenever the agents personality contradicts the stereotype.
Personality is also subject to change. The AI must be able to adapt its behavioral model to account for these changes if / when they occur.
The accuracy in which the AI is able to model behavior has a significant impact on its ability to sustain agency. If you are lactose intolerant and tell an AI with a poor behavior model of you that you are thirsty, it may bring you a cold glass of milk. The AI’s intentions are good, but it’s model of you has failed to predict that you do not want milk.
It is also important to recognize that we cannot expect these AI to be able to perfectly model our behavior. They will make mistakes. It will be up to us to accurately convey and / or clarify our choices. If you never tell the AI that you are lactose intolerant, then it is not its fault for bringing you a glass of milk. Likewise, it will be important for the AI to request clarification if it is unsure what our choice is.
Conceptualization
If all events are governed by the rule sets of physics and / or personality, then one way for us to conceptualize how to implement Agency Sustainment is from a traditional, symbolic, GOFAI perspective. In other words, imagine a giant flowchart of IF > THEN rules that our AI will use to determine what to do in any given situation.
Let’s consider a simple puzzle game environment. In this game the AI has a power level that is depleted when moving, batteries it can collect to replenish its power, coin that it can collect for points, and an exit that takes it to the next level. For this simple environment, we can have a simple flowchart such as below.

The following example level animation demonstrates how an AI using our flowchart of rules might behave. With a full battery, it prioritizes collecting coins. Once the coins are collected, it seeks power sources. Once all coins and power sources are gone, it heads to the exit. Had its battery been low at the beginning, it would have collected the battery first, then the coins, then headed for the exit.
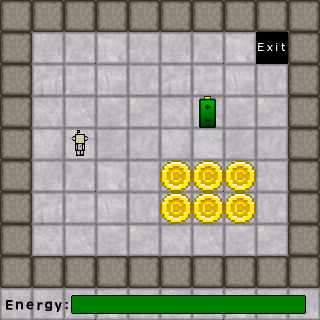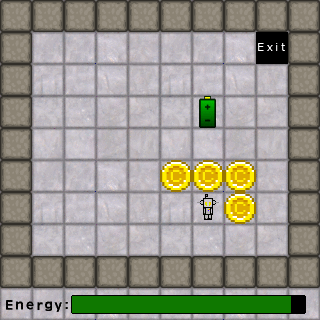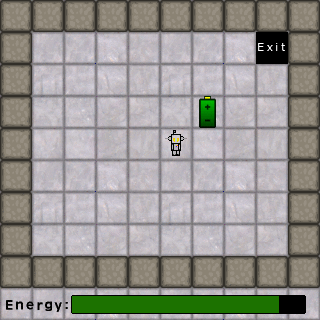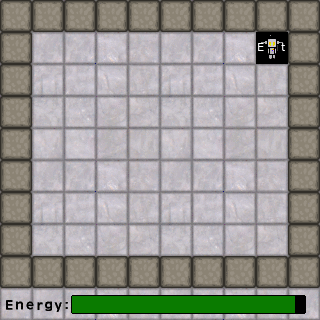
Now let’s add the human element. We’ll put a new, human character in the game whose only goal is to collect the coins and go to the exit. Each character has to take turns moving, the characters cannot share the same space, and the AI gets to move first. Let’s see what happens with our current AI:

Our poor human only gets 2 coins and is repeatedly blocked by the AI. It may seem like the AI is intentionally interfering with the human to achieve its goals first, but in fact all it is doing is following the simple flowchart. It planned to collect all 6 coins in the same movement pattern it had before. However, by the time it started collecting the top row the human had already collected 2 of the coins. Seeing that there weren’t any more coins to collect, it went for the battery and then the exit. It didn’t even take the human character into consideration during its planning. The interference was coincidental.
Now let’s add a set of rules to our flowchart that models the human character’s behavior:
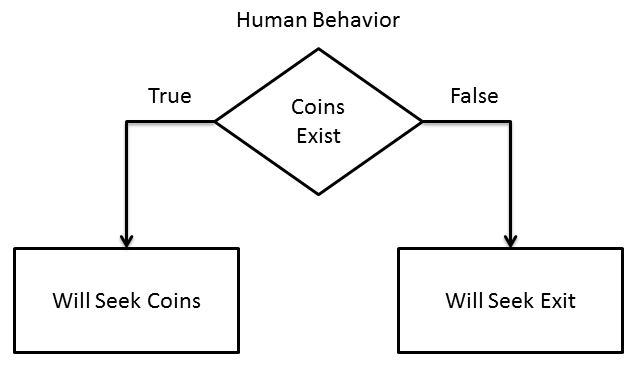
The AI can now effectively predict what action the human character will take, and can therefore include those predicted actions in its planning process. Let’s see what would happen:

This time the AI actually is intentionally interfering with the human. It can’t collect the coins if the coins get collected by someone else. Therefore it plans its movements in such a way that it blocks the human from being able to collect any of the coins. This is a Type 3 or “Sole” Agency Sustainment AI.
So far we have two simplified representations of many AI safety concerns: That an AI that is not aligned with human values may either intentionally or unintentionally interfere with human goals in pursuit of its own.
Now let’s try adding Type 1 or “Altruistic” Agency Sustainment. We can do that by incorporating the human behavior flowchart into the AI’s flowchart as follows:

Now when the AI thinks about coins, it will prioritize the human’s predicted behavior towards coins over its own desire for coins:

It will patiently wait for the human to collect as many coins as they want. In this case, our human character decided to share some of the wealth. The AI begins to move towards the coins when it sees that the human character is moving towards the exit and not seeking the remaining coins. However, it doesn’t start collecting them until the human has left the level and therefore certain that the human is no longer seeking the remaining coins. Had the human stopped before the exit and went back for the coins, the AI would have also stopped and let the human collect them.
Finally, let’s try Type 2 or “Colleague” Agency Sustainment. We’ll add a new check to see if there are enough coins that both the AI and the human can pursue their goals at the same time.
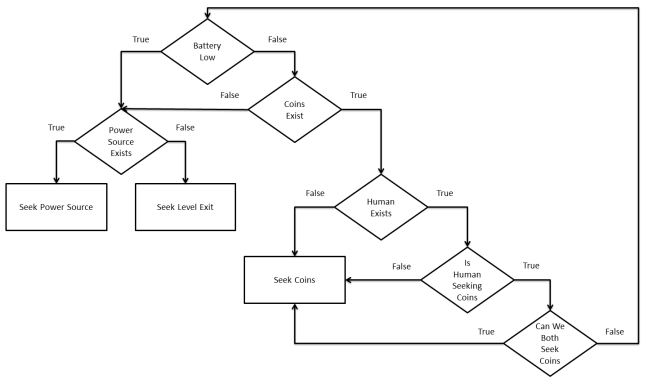
This results in a cooperative competition for the coins. Once the coins run out it will let the human collect the last one as the AI can no longer seek the coin without interfering with the human.

In this example, its need for the coins was equal to its model of the human’s need. If the human had tried to collect the battery, it would have attempted to prevent him. The AI’s need for batteries is greater than its model of the human’s need.
These examples are simplistic, but they illustrate the basic concept behind all 3 types of Agency Sustainment and how each type might align (or interfere) with the human character’s goals when those goals overlap its own.
However, it’s important to note that implementing Agency Sustainment using traditional, symbolic rules that we “program” into our AI is not realistic. A real AI will need to be able to learn all of these rules on its own without the need to pre-program them in.
Thought Experiments
We’ve seen how the concept works in simple examples, so now let’s extrapolate the concept into more complex situations and attempt to reason what the results might be.
Experiment 1: Diamond Boxes
This thought experiment was authored by Eliezer Yudkowsky in his paper Coherent Extrapolated Volition. There are 2 boxes, A and B. In one of the boxes is a diamond. You only get to choose one of the boxes. The AI knows that box B has the diamond. You tell it you’re thinking of choosing box A. The AI should be able to know that you really want box B and tell you to choose it instead.
We’ve touched on influencing agency in a previous section. As long as the AI has a reasonably accurate behavior model of you, it will recognize that the reason you are choosing a box is not because you want a box, but because you are seeking the diamond it may contain. It will tell you to choose box B instead.
Let’s say that the you and the AI both want the diamond, and the AI gets whatever box you don’t choose. A Type 1 AI will happily tell you to take box B anyway, as your desires override its own. A Type 2 AI will weigh why you want the diamond against why does. If it finds that the reason it needs it is greater than the reason you need it, it will tell you to stay with your choice of box A. If it finds that you need as much or more than it does, it will tell you to choose box B. A Type 3 AI will just tell you to stay with box A.
Experiment 2: Malicious Intent
What if we were to give the AI a harmful instruction? Suppose we really like our neighbors car. So we tell our AI to steal it for us.
A Type 1 AI would refuse. Ownership of the car is a choice that your neighbor made. The AI doesn’t only sustain the agency of its owner, but the agency of everything (including other AI agents). Stealing the car interferes with the choice your neighbor made to buy their car. The AI might instead suggest that you buy the same car from a dealership or offer to purchase the car from your neighbor.
A Type 2 AI would not steal the car unless it also needed the car (more that it thinks the neighbor does) and there was no viable alternative.
A Type 3 AI would simply ignore the request. Though if it wanted the car, it would steal the car for itself.
Experiment 3: Conflict
Adam asks our AI for apple juice. John hears the request and asks for some too. There is only enough apple juice for one person. Who does the AI give the apple juice to?
Both a Type 1 and Type 2 AI would give the apple juice to the first person who requested it, Adam. If John was fast enough to get to the apple juice before our AI then it would try to talk John out of taking it, but would not stop him. The AI would otherwise leave it to Adam and John to settle their dispute. Or, if the AI knew that John liked apple juice a lot more than Adam it would see if Adam would be willing to choose an alternative so that John could have the apple juice instead.
A Type 3 would ignore the request unless it was incentivised in some way. If it was, it would, like the other types, give it to whoever asked first. However, it would not care if the other person wanted it more or who got to the juice first.

One thought on “Friendly AI via Agency Sustainment”