In the previous article, Friendly AI via Agency Sustainment, we talked about a potential solution to the Control Problem of Artificial General Intelligence. One of the requirements of that proposition is an AI that is capable of predicting the behavior of other agents. In this article, we will discuss how humans make such predictions and how that can be applied to an AI.
Elements of Prediction
In any non-static environment there will be a range of changes that will occur within a given frame of time. A clock will tick, a bird will sing, a student will study for a college exam, the Earth will complete a revolution around the Sun, and so on. All these changes are based on causality. The causes may be simple, like gravity pulling an object from a table to the ground, or they may be complex, like the reason a cat knocked said object off the table. Regardless of the complexity of the cause(s) that drives the change, once the cause(s) occurs the change will follow.
Predictions are an attempt to model what changes will occur in a future period of time. These models are based on only two elements: observation and knowledge. Observation of an environment in some state, and knowledge of causes and effects within that environment.
The medium of the environment is irrelevant. It can be the physical world, a digital world rendered in a computer, or an imaginary world pictured in our mind’s eye. As long as we have knowledge of what causes changes in that environment and what those changes will be, we can predict future states of that environment.
The knowledge does not need to come from direct experience in the environment either. You can study a wilderness survival guide and be able to accurately predict which wild mushrooms you can eat and which will make you sick. You can watch a gameplay video online and be able to predict how a videogame level will need to be played in order to win. You can imagine a world where gravity is suddenly reversed and predict that you would need to hold on to something to keep from flying off into space.
Precision v. Accuracy
Predictions can be precise if you know the causes of change and have time to process them. A structural engineer can accurately predict how much weight their building can hold because they have knowledge of the limits of the materials and have had the time to calculate all of the contributing factors. Predictions can also be imprecise if not all of the causes are known (or knowable) and / or there is not enough time to process them. Such as if someone next to you suddenly shouts “Duck!”, you predict that something is heading towards the upper half of your body from somewhere at some speed.
Precision does not guarantee the accuracy of the prediction though. For example, there may be a manufacturing defect in the steel that caused the engineer’s prediction to be inaccurate and the building collapses under far less weight. Whereas your imprecise, split second prediction that something was headed toward you was accurate, and by ducking you saved yourself from getting hit with an errant football.
Structure of a Prediction
Because predictions are based on causality, they can easily be represented as symbolic rules. IF the sky is clear THEN it will be warm outside.

However, this is an extremely abstract symbolic representation. An actual prediction can have a multitude of factors. IF the sky is clear AND it is summer THEN it will be warm outside.
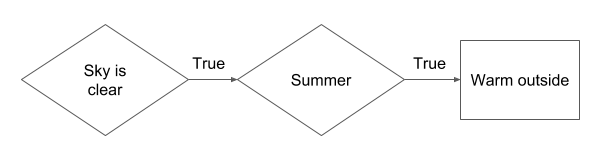
The state of each symbol can also have an affect on the prediction. IF the sky is clear AND it is summer THEN it will be warm outside ELSE IF it is winter THEN it will be cold outside ELSE IF the sky is not clear THEN it will be cold outside.

Obviously there are substantially more factors that go into the prediction of whether or not its going to be warm or cold outside than I’ve diagrammed here. These symbolic rule sets can quickly become immense in size and complexity even at a highly abstract level such as this. It gets exponentially worse if we peel back the layers of abstraction, as nested inside each of these symbols is another, less abstract symbolic rule set that determines whether the state of the original symbol is true or false.
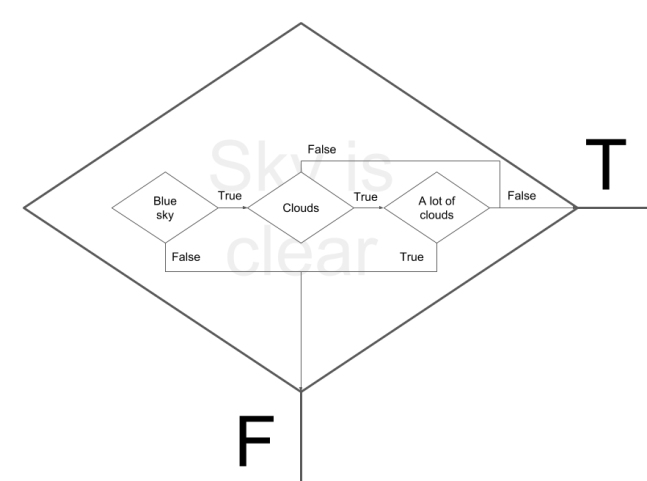
And nested inside each of these less abstract symbols is an even less abstract symbolic rule set. These nested rule sets continue all the way down to the individual, sub-symbolic input signals that come from our nervous system. For example, IF a group of white retina signals is surrounded by a group of blue retina signals THEN you are looking at a cloud.

However, you can’t infer that from just one small set of your inputs. You have to take all of your inputs into account. Maybe you’re not looking at the sky at all, but at white letters on a blue paper. Or a picture of a sky, which may not help you determine if it will be warm or cold outside.
In the above examples, we’ve analyzed a prediction from a top to bottom approach. We started with extremely abstract symbols and picked apart layers of abstraction until we hit raw sensory inputs. However, the level of complexity and the range of possible alternatives is near infinite. It would not be possible to model them all and try and fit them to whatever our current sensory inputs are. Therefore when making a prediction we take the opposite approach and go from the bottom up. This is where pattern recognition comes into play.
Constructing a Prediction
We don’t look at a red cup of coffee and think “Is it a cloud? No. Is it a car? No. Is it a tree? No. Is it…”. Instead, we match the patterns of signals from our nerves to our knowledge database of the world using those patterns as our search filters. “It’s red, vertically cylindrical, 4 inches tall, hollow, has a loop on the side, is filled with a black liquid, the liquid is steaming, it is sitting on a table, and smells like coffee. What have I experienced before that resembles all of these inputs? It’s a coffee cup.”
We have observed an object in the environment, matched it to an object that we have knowledge of, and can now make predictions about it using the associated knowledge. It will remain stationary, it will continue to smell like coffee, it will be hot to the touch, it will taste like coffee, etc…
This is easy enough for objects with no agency of their own. They will always obey whatever the rules of their environment are. Such as the laws of physics. As long as we know how those rules apply to an object, we can accurately predict what that object is going to do with relative ease.
That isn’t always the case with objects that have agency. An agent’s behavior is still subject to the rules of their environment, but their actions are also determined by the invisible, subjective rules of their personality. An agent cannot decide to no longer be influenced by gravity, but unlike the coffee cup that will always remain on the table, an agent can decide to counteract gravity by jumping. This can make predicting the future of an agent a much more difficult task.
However, just because the rules of an agent’s personality are invisible that does not make them unknowable. If Bob is in gym wear, has a jump rope in his hands, and is swinging the jump rope it is easily predictable that he is about to jump. If Bob is in a business suit, is attending a business conference, and has his hand raised it is easily predictable that he wants to speak. These predictions are all made from the knowledge that we have gained from similar observations.
Learning Knowledge
We are not born with the knowledge that we use to make predictions. We have to learn it by observing our environment and the changes that take place within it. But how does this work?
It’s very difficult for us to look objectively at our own learning mechanisms. We don’t remember how we learned the majority of everyday common sense knowledge. We were too young when we learned it to be able to introspectively analyze our thought processes. And now that we’re older, we have so many priors in our knowledge database that we can quickly analyze new objects and environments and accurately predict what they are and what they will do.
Let’s do a simple exercise. Take a moment to study the following video game scene:

If you’ve played games before you can make some instant predictions about how this game will work, but for the sake of the exercise answer the following observational questions:
- Who is the player character?
- What is the thing with the circle?
- What is the blob with legs?
- What are the white things?
- What is all the blue stuff?
- What is the stuff along the bottom of the screen?
- What are the red things?
- What is the stuff that’s under the red things?
Now let’s make some predictions:
- What objects will move?
- How will each object move?
- How will each object interact with the other objects?
- How do you win the game?
- What video game(s) are you basing your answers off of?
Do not read further until you have answered the questions and viewed the gameplay animation.
Not quite what you predicted? That means your mind is creating a new entry in your knowledge specifically for this game.
Now, when you look at the following scene what do you think will happen?

Whatever your predictions are, they are based on your new knowledge gained by observing the rules of this particular game environment. But that knowledge is pretty limited. You only saw a small part of the gameplay. You may still struggle with some questions like “How do you win the game?” and “How will each object interact with the other objects?”. To find the answers, you would need to observe more of the game.
Surreal environments that defy common sense are a useful tool for reverse engineering how we form new knowledge and use that knowledge to make predictions. Let’s take a look at what just happened.
You were exposed to an unfamiliar environment. You matched elements of the environment to similar environments from your common sense knowledge of video games. You made predictions about the unfamiliar environment by assuming that the unfamiliar would behave in a common sense way. When it did not, what did you do? Did you laugh? Did you groan? Did you study the new environment to learn its rules or did you dismiss it as absurd? There is no right answer to these questions. Different people will have different reactions. However, whatever your reaction was, when you looked at the image of the second scene you did not re-apply your original set of predictions.
If we had studied the environment, a reasonable prediction would be “The circle guy will fly up and collect the squares above the pulsing blob.” But how are we making that prediction? We saw that the circle guy can move instantly a small distance in one of four directions. We saw that when the circle guy touched the squares they disappeared. We saw that the blob pulsed.
Those are all visible, causality based environmental rules that are easy enough to predict, but how are we predicting where the circle guy will move? How do you predict the behavior of something that has agency?
When predicting the behavior of an agent, we have to make a lot of assumptions. Unlike the objective nature of environmental rules, the internal rules of an agent are subjective. Since the circle guy collected all the squares in the animation, we can assume that the squares are desirable to the circle guy for some reason. Do they provide a reward? Are they necessary to complete the game? We don’t know. We may never know. All we know is that we saw the circle guy collect them. From this limited amount of observational data, we can make the assumption that the circle guy will again move to collect the squares.
Predictions of the subjective rules of an agent are, themselves, subjective to your own experiences. Perhaps you’ve played a lot of surreal games in the past and have experienced that every action in these kinds of games has a purpose. So you predict that the circle guy will first move to touch the red diamonds before moving to collect the squares since that is what happened in the first animation. Even though there was no observational data to suggest that the red diamonds do anything, your past experience with other surreal games infers a causal relationship between touching the diamonds first and then collecting the squares.
However, if we dismissed the new environment as absurd, our prediction about the second scene may be “I have no idea what will happen.” We only observed it enough to see that it did not conform to our original predictions. The only knowledge we have learned about the environment is that it’s nonsensical. But even “I have no idea what will happen” is a useful prediction in and of itself. We are predicting that it will not conform to our common sense. We don’t have the knowledge to predict what will happen, but we do have the knowledge to predict what won’t.
Agents Predicting Agents
Because the personality rules that govern an agent are both subjective and invisible, it’s impossible to be completely certain when predicting another agent’s behavior. However, it is possible to be reasonably certain just by observing behavioral patterns. The more consistent a behavior is, the easier it is to predict when that behavior will occur. Let’s look at an example.
Bob is a regular at “Suzy’s Diner”. Suzy has observed that every Sunday at 1pm, Bob comes in and orders a large stack of pancakes. He always has a smile on his face and he tips well, so Suzy enjoys his patronage. One Sunday, she had the cook make a large stack of pancakes for Bob before he even set foot in the door. Bob was thrilled. From then on, Bob’s pancakes were waiting for him every Sunday.
How did Suzy predict that Bob would want pancakes before he was there to order them? How did Suzy know that it would make Bob happy? How did Suzy know when to put the order in? Why doesn’t Suzy pre-make pancakes for all of her customers?
In her mind, Suzy created a set of rules specifically for Bob based on her observations of his behavior. She uses this rule set to guide her own behavior.

One Sunday, Bob thinks to himself “I wonder if they make a good chicken fried steak?”. Being the gentleman that he is, he calls ahead to Suzy’s Diner to let her know that he is going to try the steak instead of pancakes today. Why would he do that?
Bob has his own rule set for Suzy’s behavior based on his observations of her behavior toward him. He knew that she would predict that he would come in at his usual time and want his usual pancakes. He knew that if he wanted steak instead, he would need to communicate that to Suzy otherwise she would waste a perfectly good order of pancakes.
But now there is a problem. Suzy’s existing rule set for Bob is no longer accurate. She must expand and update her rule set to include her new observation that Bob may not always want pancakes.
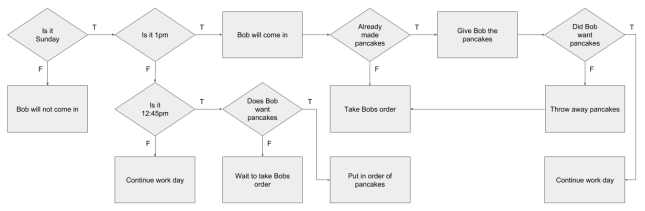
There is another problem too. If Bob does not call Suzy to tell her his order before 12:45pm, she does not have enough information to accurately assess whether “Does Bob want pancakes” is true or false. She could attempt to determine a probability based on the number of times she remembers Bob wanting pancakes vs the times Bob has wanted something else and use that to make her prediction, but there is a better alternative. If she waits to take Bob’s order, she will know for certain whether he wants pancakes or not. But how does she determine that waiting is preferable?
She models the outcome of both possibilities and determines which one produces the best results. This is commonly known as a “cost-benefit analysis”. In this case, waiting to see what Bob orders is much more beneficial than throwing away unwanted pancakes and then taking his order anyway.
That’s not to say that probability is not a factor in assessing whether an ambiguous condition is true or false. Sometimes the high frequency of one outcome outweighs the higher benefit of a low frequency outcome. Like if Bob went back to always ordering pancakes.
Current Predictive AI
There are a multitude of decades old techniques that are capable of creating AI that can make predictions about its environment, and even predict the behavior of other agents in that environment. These techniques are called Good Old Fashioned AI (GOFAI) and use symbolic rule sets similar to what we’ve talked about. They are by far the most common type of AI currently in use, and can produce anything from rudimentary to incredibly complex life-like behavior.
The problem is, these rule sets have to be hard coded into the AI by its programmers. Which means that they can’t adapt to anything that their programmers haven’t given them a rule for. When a GOFAI agent encounters an unexpected situation, it completely breaks down.
What we need is a GOFAI agent that learns its own symbolic rule sets. Just like Suzy and Bob, it has to be able to make observations and interpret those observations into sets of rules that it can use in the same ways that a traditional, non-learning GOFAI uses the rules that its programmers gave it.
Creating Symbols
Let’s say that we are sitting in front of a computer game that has four unlabeled buttons.

In order to find out what these buttons do, we have to experiment with them. So we’ll push one to see what happens.

We observe that when the first button is pressed, the character on the screen moves up one grid space. Fortunately for us, we have a lot of prior knowledge that lets us immediately create a high level symbolic rule for the cause and effect relationship between pushing the button and the character moving:

If we diagram this symbolic rule, we get something like:
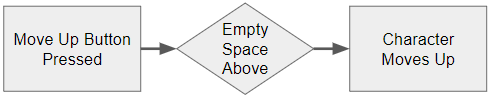
Our prior knowledge even lets us infer additional rules without the need to observe them beforehand. For example, we can infer that the walls around the edge of the level will prevent us from leaving the play area:

Once we’ve experimented with and observed the causal relationships between pressing each button and the changes on the screen, we’ll have learned how to interact with the environment.

Now let’s take a look inside this game from a programming perspective. To create this game we have to tell the computer how to change the image on the screen when a given button is pressed. We could take a huge amount of time and effort to write thousands of instructions in raw binary machine code, but we have powerful tools available that allow us to abstract binary code into high level symbolic programming languages that are magnitudes easier to work with. For example, we can use a “game engine” and only have to write a few symbols like:
IF button_pressed(1)
character.y -= grid_space
The game engine then does the work of translating our high level symbols into lower level symbols which are then translated into even lower level symbols until they are finally translated into the thousands of lines of binary machine code. The computer then processes the machine code which changes the pixels on the screen.
Whereas when we are making an observation, we are translating in the opposite direction. Instead of translating symbols into changes, we are translating the changes into symbols. Let’s take this “from change to symbol” translation and apply it to an AI.
We’ll take the same game and see what kind of symbols and rules the AI would create. We’ll start off with a completely clean slate. The AI is given four actions that it can perform and only the raw pixel data from the screen as sensory inputs.

Like us, the AI must first try an action so that it can make observations about what the action does.

Unlike us, it has no prior knowledge to create a high level abstracted symbol like “Move Up”. Instead, its symbols consist of the raw values of its inputs before the action, and all of the changes that occurred in the inputs after the action. The raw input values are the condition that its inputs have to resemble for the associated changes to occur.

Just by performing one action, our AI has learned its first symbolic rule. It can use this rule to begin making predictions. Let’s say the AI finds itself in the following situation:

The values of its inputs do not perfectly match the conditional symbol in its rule, however it has no other conditional symbol to compare against. Therefore it accurately predicts that if it uses its first action, the environment will change as it does in the change symbol:

But what would it predict if it used its first action now? It doesn’t have any prior knowledge to use to infer other types of interactions like we do. There isn’t even another conditional symbol to compare against. So it can only predict that the one change that it has observed will occur again. However, there’s a problem. That change has the player moving from the lower grid space to the empty grid space above, but there is no empty grid space above. So it predicts that the player will simply vanish!

Instead, the player just doesn’t move at all.
The AI’s prediction was wrong. It has to create a new rule for the new observation just like we did earlier when our predictions about the surreal platform game were wrong.
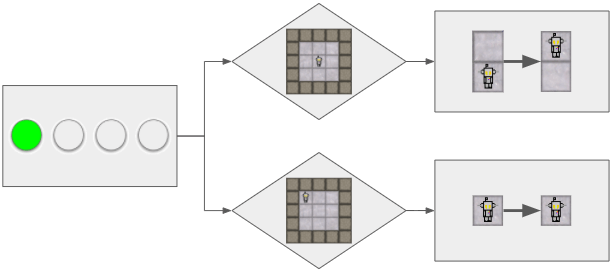
Now that there is another conditional symbol, the AI has something to compare the current state of its inputs to. It bases its predictions on whichever conditional has the closest resemblance to the current state.
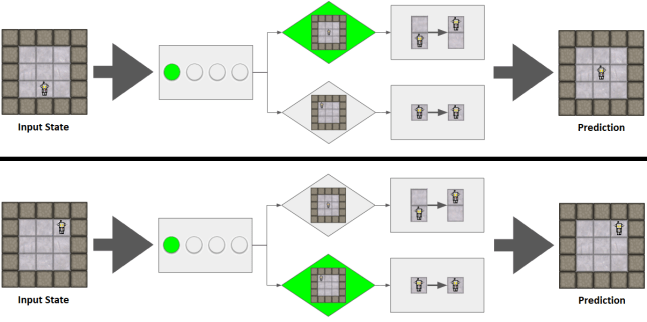
As more and more elements are introduced into the game (keys, doors, hazards, collectibles, etc…) the AI creates more and more conditional -> change symbolic rules.

Modeling Predictions
Once the AI has at least one symbolic rule, it can model sequences of predictions that it can then use to make plans. Let’s say that the game has a collectible battery that the AI wants. Assuming that it has already created all of the necessary rules, it can model a sequence of actions to predict what it needs to do to get to the battery. It starts by modeling an action from its current state.

It’s not actually performing the action. It’s just imagining (modeling) what would happen if it did. It then makes another action prediction model based on the previous model instead of the current input state.

It continues to generate new prediction models until one of the models achieves its goal of collecting the battery. Then all it has to do is actually perform the sequence of actions that it modeled.

The process of modeling a plan from predictions is rarely as streamlined as the example above. The AI is generating sets of predicted states which it must evaluate to determine whether or not the predicted state is close to the desired goal state. As a result, many of the generated predicted states end up unused and discarded. A more realistic diagram of the modeling process looks something like this:

Complex behavior emerges from this ability to model sequences of actions based on self-generated symbolic rules. For example, in this excerpt of test footage an AI is easily able to navigate through a series of obstacles to achieve its goal of collecting the battery.

The AI is able to automatically determine the sequence of sub-goals necessary to achieve it’s goal just by modeling predicted states.
In this example, it first modeled its way up to the door by the battery. When it modeled its interactions with the fire it predicted that it was not able to move through the fire until it collected a fire extinguisher. It back-tracked in its models and tried modeling its way to the nearest fire extinguisher which if found was also behind a wall of fire. It back-tracked further toward the fire extinguisher behind the locked door. It then modeled its way to the closer key which was again behind the wall of fire. So instead, it modeled its way through the one-way arrows to collect that key, which it then modeled using to collect the first fire extinguisher. It then modeled using that fire extinguisher to put out the fire near the locked battery door. Which is when it modeled itself needing yet another key which it could not go back and get. So it back-tracked again, modeled itself collecting both the key and the fire extinguisher and using them to finally gain access to its battery. Once it found a successful sequence of models, then all it had to do was perform the corresponding sequence of actions.
Observing Other Agent Behavior
So far in these examples, the AI has been the only agent in the environment. The symbolic rules it has generated have been for objects that have no agency of their own. What would a symbolic rule for behavior look like?
Let’s add a human controlled character into our game. We’ll also add “coins” that the human wants to collect. For clarity of the example, we’ll have the AI character just sit still and observe.

The AI observes that the human character moves toward and collects the coin.

There are several changes that the AI will observe. The human can move to the right, it can move up, and it can collect the coin.
Let’s take a look at the first rule that the AI makes:

It looks a lot like any other rule. The main difference is that the pixels that change are the human’s and not the AI’s.
From this one symbol, the AI can model a prediction about what the human will do next. It predicts that the human will continue moving to the right.

From the animation, we know that is incorrect. The player moves up instead. So the AI makes a new rule:

The AI attempts to make another prediction by matching the current state to the closest conditional it has.

Again, it finds that its prediction is wrong. So it makes yet another rule.

Even though the new rule’s change is the same as another symbol, the conditional is not. This makes it a unique rule.
It ends up creating a new rule for every state that the human is in, as every prediction that it makes turns out wrong. In the end, its rule set looks like this:

Now if we restart the level, it would be able to predict where the human would move. However, we humans are fickle creatures. Maybe this time we want to take a different path:

The AI’s predictions of how we’ll move is accurate until we move up from the middle instead of to the right. So once again, the AI has to make some new rules for the new observations. The new rule set looks like this:
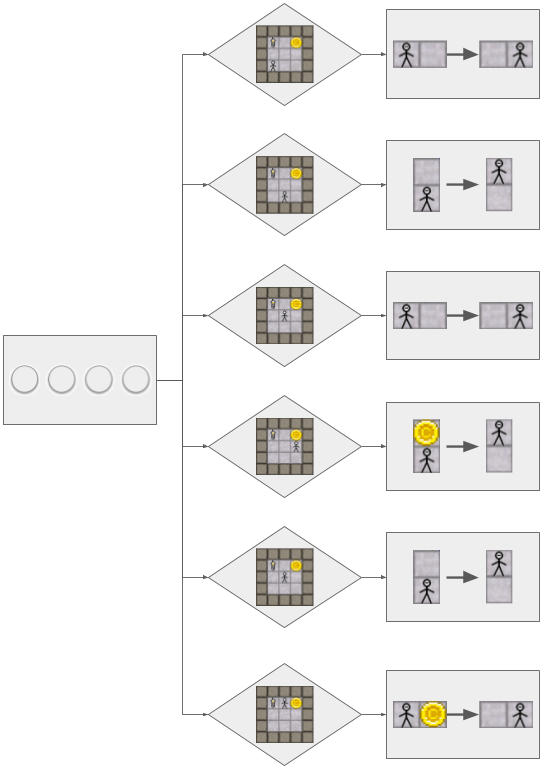
Here’s where things get a little more interesting. Notice that there are now two conditionals that are the same (the human in the middle of the level), but with different changes. That means that the AI has observed two different outcomes for the same cause. So how does it determine which direction to predict the human going?
Think back to when Suzy had to determine whether or not Bob was going to order pancakes. Instead of just assuming what Bob wanted, she modeled both outcomes and determined which one was preferred.
The AI must do the same thing. It must model the human going both directions and see if one outcome is preferable to the AI over the other. Since both outcomes ultimately result in the human collecting the coin, the AI has no preference. And because the AI predicted both outcomes, it doesn’t matter which direction the player ends up going for the AI to have made an accurate prediction.
Generality of Self-Generated Symbolic Rules
An AI that utilizes self-generated symbolic rules to make predictions is also not limited to one domain. Each rule is based on the AI’s raw sensory inputs at the time of the rule’s creation. This means that rules from different environments can seamlessly co-exist.
Let’s expand the domain range of the previous AI to include MNIST character recognition. We’ll make a new environment where its inputs are the pixels of a character from the MNIST dataset and an “answer” input that can either be “NULL” or the correct answer in the form of an integer (0 – 9). When the AI is first shown a character, the answer input will be NULL. When the AI performs an action, the answer input will change to the correct integer of the character. The AI will still have the original four actions that it can perform, but in the MNIST domain all of the actions do the same thing: reveal the answer.
Let’s drop our existing AI with all of its puzzle game rules into this new environment:
![]()
Our poor AI doesn’t know what to do! Suddenly, none of its inputs are anywhere close to its existing rules. It will still find one of its existing conditional symbols to be marginally closer than the others, but the pixels to change don’t exist so it can’t model anything anyway. Since it can no longer model a prediction, it goes back to experimenting with its actions to see what happens.
When it performs the first action, it observes that only one of its many sensory inputs changes from NULL to a number. It now has its first rule for MNIST:

Now if we show it another number, no matter what that number may be, it will predict that the “answer” will be 4. The “4” conditional symbol will be a much closer match to any new number than any of the puzzle symbols. If its prediction is wrong and the new answer is not 4, it will create a new rule for the new number until it has enough rules to accurately predict the answer of any given number.
One of the advantages to this method is that at any time, we can take the AI out of the MNIST environment and put it back in the puzzle game and it will automatically return to using the puzzle rules (or vice versa).
The AI can also create, use, and store any number of symbolic rules from any number of domains. The process behind using symbolic rules to model predictions is domain agnostic and depends solely on matching the current raw sensory inputs to the symbols stored in its rules.
Transparency and Control of Symbolic Prediction
One of the main concerns in AI safety is system transparency. We don’t just want an AI that can make a decision. We want to know why the system made that decision.
With symbolic rule based predictive AI we can trace the exact reasons why a system acted in a particular way. We can log how and when it learned its symbols. We can examine and even directly manipulate its rules (Like changing NULL > 4 to NULL > 5 to have it now recognize 4’s as 5’s). We can even take a look inside the “mind’s eye” of the AI and monitor the predictions that it generates and the plans it makes. This gives us the potential to intervene if some aspect of its plan is undesirable before it acts.
In the following test footage excerpt, we can see what actions the AI is planning to do on the right side of the screen before any action is taken in the actual environment on the left side of the screen:

If for some reason we didn’t want it to collect that battery, we could force it to make another plan instead. It could also easily be designed to loop in this planning state forever with a prompt that requires human approval to break it out of the loop before it actually perform its actions.
This intuitive, high level of transparency and human control over the AI is ideal for assisting in AI safety. Though it’s important to recognize that these features alone do not solve safety problems. They are just tools to help.
It’s also important to recognize that these features are not required for the AI to function. It is possible to remove transparency by intentionally obfuscating or encrypting the symbols or rules, and human intervention points have to be purposefully designed into the system.
Final Thoughts
These examples are just basic toy problems with easy answers. It will take further research, development, and testing to see if this method will scale to more complex / real world problems and predictions.

{kind=link}